In a Nutshell
Who: Public speakers, politicians, aspiring TED talkers, and (potentially) writers
WHY: Public speakers often need to rapidly evaluate how various ideas and different articulations would resonate with audiences.
HOW: GPT-2, Word Embeddings, Predictive Analytics, Natural Language Processing, Support Vector Machines
IMPACT: Public speakers can now rapidly explore the idea space and get an idea of what ideas create the most “buzz” or audience engagement.

1. Introduction

Actually giving a speech in front of an audience can be scary; however, what is even more daunting is identifying a topic to speak on. However, with the recent advances in text generation by transformer-based models such as GPT-n, BERT, and others, this is a problem that can be mitigated. However, a potential speaker then immediately faces a second problem: which ideas would generate the most audience engagement? The goal of a TED talk is often to share original, thought provoking ideas with as large an audience as possible. Here is where predictive text classification/regression approaches may be helpful. Thus, in this paper, I will discuss a NLP-based system I built that is capable of helping speakers deliver better, more compelling talks.
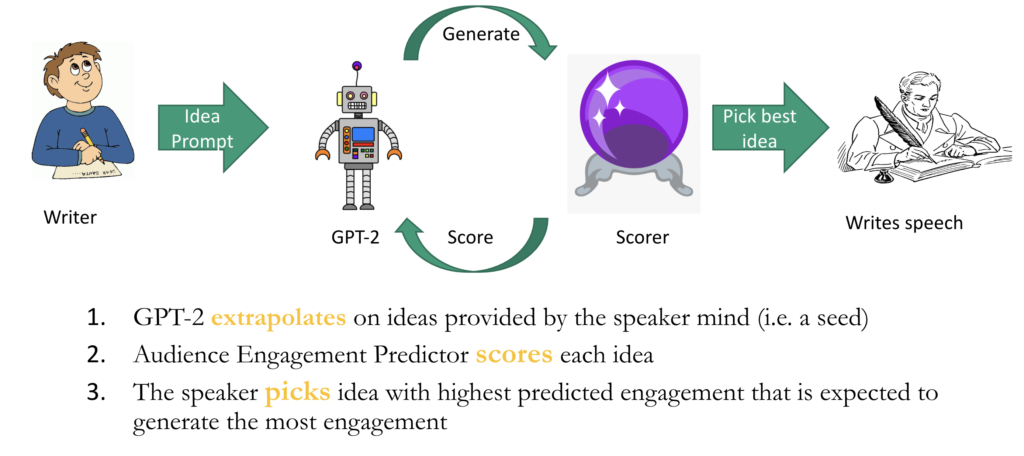
2. Related work

Transformer models rely exclusively on self-attention mechanisms, using a stacked Encoder/Decoder architecture (Vaswani et al., 2017). They have become especially popular in the NLP community since their introduction. In particular, the OpenAI foundation in 2019 proposed an 1.5B parameter Transformer called GPT-2 trained on 8 million web pages (40GB of Internet text), in an unsupervised fashion(Radford et al., 2019). The goal was to create a language model capable of generating conditional synthetic text samples, when primed with an input. One of the next steps mentioned by the authors as a potential application of GPT-2 is as an AI Writing Assistant. My project is inspired by this suggestion. Along with Transformers, an equally popular research theme in NLP community centers around the use of word embeddings. Word embeddings have become a common way to convert words into vector spaces, while preserving semantic & syntactic structure; one of the first word embedding techniques was word2vec (Mikolov et al., 2013). In addition to word2vec, common embeddings include BERT, GLoVE (Pennington et al., 2014), etc. Each of these embeddings confers a particular advantage. For example, BERT embeddings take into account a word’s context while generating an embedding through the use of a two-phase training process, namely, Masked Language Model, and Next Sentence Prediction(Devlin et al., 2018).
However, each of the embedding approaches discussed above involve embedding a word into a vector space. Often, the requirement is to embed an entire document into the vector space. One approach is to simply compute a weighted average of the word vectors in a particular document, and take that as the document’s embedding into the vector space. While this approach may sound simplistic, this simple ”averaging of word vectors” approach is capable of outperforming other sophisticated supervised methods such as RNNs and LTSMs. For example, this simple weighting method has been shown to improve performance by 10%-30% on textual similarity tasks (Arora et al., 2016). However, one of the major disadvantages of such averaging approaches is that that they completely ignore word order, and hence map two sentences with the same words to the same region of vector space, even though they might have completely different semantics (Le and Mikolov, 2014). Doc2Vec is proposed as a document embedding technique that is capable of embedding variable length input segments, and which also takes into account word order (Le and Mikolov, 2014).
3. Dataset
The dataset I used consisted of TED Talks from 1972 to 2017, taken from the TED.com website. Though TED was officially founded on in 1984, the TED.com website hosts archival footage of some of the earliest unofficial talks given by luminaries such as Victor Frankl, Richard Feynman, etc. Each talk is represented by a row in the dataset, and associated metadata such as event name, speaker name, talk title, speaker occupation, etc. are represented as columns. Of special importance to us is the transcript of each talk, which was transcribed by a professional human scribe. Another relevant metadata is the ”number of comments” that a given talk generated in the comments’ section on TED.com. This is important because I operationalized a talk’s ”audience engagement” as the number of comments associated with it on the TED.com website. My rationale was that talks that were more thought provoking should generate more comments. The general shape of the data was 2550 talks, and 17 associated columns, plus one additional column containing the transcribed text of the talk.
4. Methodology

4.1 Exploratory Data Analysis
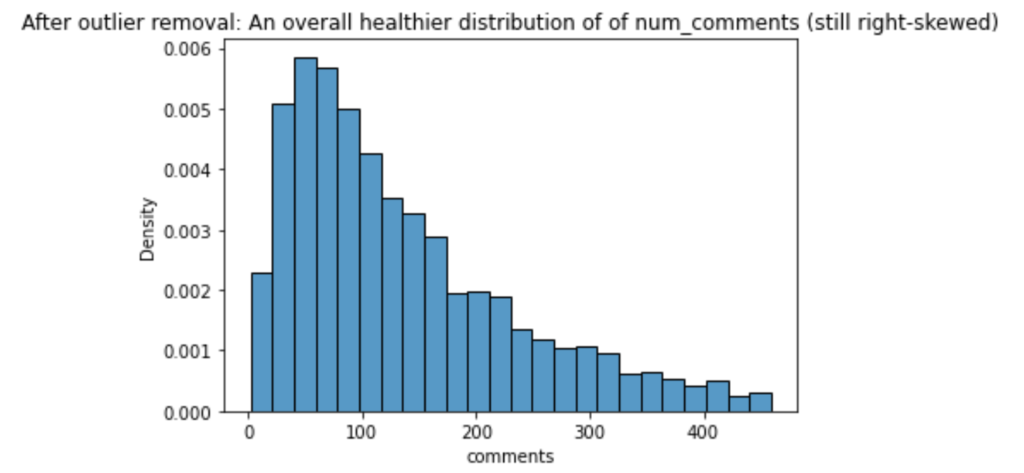
I first began with a brief exploratory data analysis. The goal was to understand the nuances intricacies of the dataset in order to build a better predictive model. My first objective was to understand the distribution of the number of comments. This is important since this will be our target variable. As can be seen in the figure below, the distribution of comments is exponentially distributed, with a strong right skew. An average TED talk generates about 200 comments, with a large standard deviation (300) between talks. Moreover, the minimum number of comments for a talk was 2, while the maximum number of comments for a talk were 6404. This indicates the presence of outliers, which I removed using the 1.5 x IQR rule. In other words, if a talk’s number of comments was greater than Q3 + 1:5 IQR or lesser than Q1 – 1.5 x IQR (whereQ1, Q3, IQR represent the 1st quartile, 3rd quartile, and inter-quartile range of the data), then it was deemed an outlier and removed from the dataset. Outlier detection and removal is important in building predictive models as it ensures that individual rare points do not adversely affect the overall fit of the model. 200 outliers (7.84% of dataset) were removed. After outlier removal, we observed a healthier (though still right-skewed) distribution of the target variable, as can be seen in the figure below.
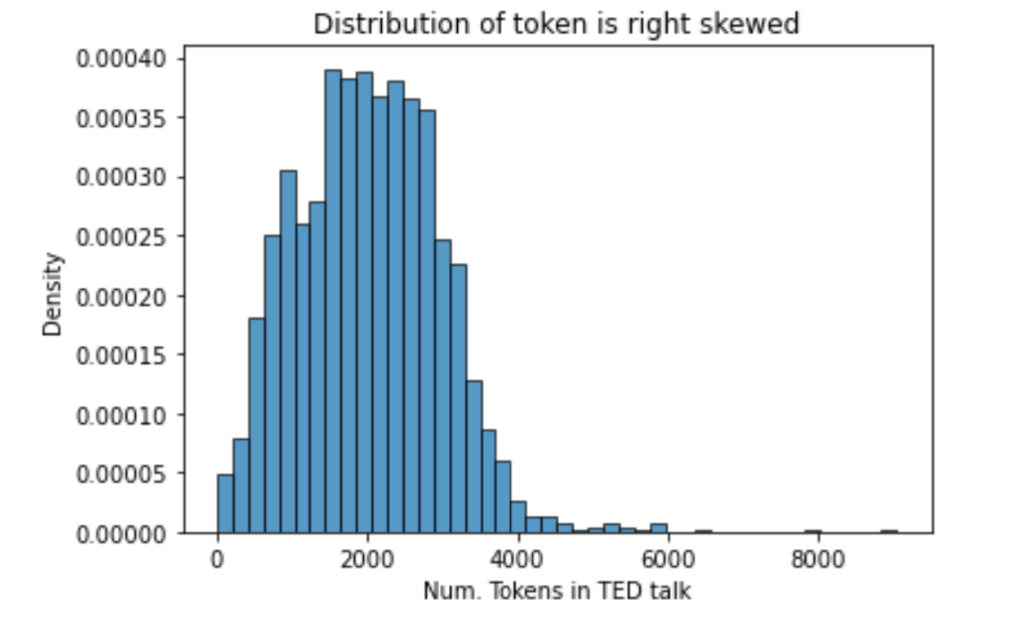
I then proceeded to understand the length of a talk, measured by the number of words; the overall distribution of a talk’s length is a roughly normally distributed with a slight right-skew. This is visible in the figure immediately below. The average talk contained about 2000 words (mean=2003,median=1981, sd=950).
4.2 Audience Engagement Prediction
To build the audience engagement predictor, I used the scikit-learn ML library. It has some great functionality to build various types of ML models, and then test them. I also used scikit-learn’s wrapper methods for Liblinear (logistic regression, SVM) and xgBoost (boosting).
4.2.1 Feature Engineering
My first step was to engineer features to help in the predictive modelling stage. I chose to explore 4 different types of features, which were (1) count vectorization, (2) tfidf vectorization, (3) doc2vec embedding, and (4) GLoVE embedding. For the count, tfidf vectorizations, I chose to further explore various n-gram extractions, for n = 1,2,3,4. Meanwhile, for the doc2vec and GLoVE embeddings, I chose to explore 50, 100, 200, 300 dimensional embeddings. In total, I generated 16 different feature sets to experiment on. Instead of using word2vec to generate individual word vectors and then taking a weighted average of word vectors as a representation of a talk, I decided to use doc2vec because it is known to generate better embeddings. As explained in (Mikolov et al., 2013), a simple averaging of word2vec word vectors completely ignores word order within a sentence. My motivation behind using GLoVE pre-trained embedding was to evaluate how effective pre-trained embeddings would be on this prediction task. I chose a GLoVE embedding pre-trained on Wikipedia- 2014 and Gigaword-5 datasets. This consisted of 6 Billion tokens, a vocabulary size of 400,000 uncased words. It is capable of producing embeddings of dimension 50, 100, 200, 300, each of which was explored in my subsequent experiments.
4.2.2 Experiments
I started out by dividing the data into a train, test sets using a 70/30 split. For the model development experimentation, I tried out 5 different models (logistic regression, support vector machine, k-nearest neighbors, random forests, and boosted trees). For each individual model type, I specified a range of hyperparameters to test. This generally included regularization parameters (L1 vs L2 regularized loss, C tradeoff for SVM) as well as model specific hyperparameters such as number of boosting iterations for boosted trees, and the number of features to randomly consider at each split of a tree in the random forest. For each combination of hyperparameters, I recorded the mean absolute error (MAE = 1/n*sum(abs(y_i – y_hat_i))) and the mean absolute percentage error. (MAPE = 1/n * sum(abs(y_i – y_hat_i)/(y_i))*100). I selected the best model as the one with the lowest MAE. In total, I tested 80 models (16 feature sets for each of 5 model types).
A model was evaluated by first tuning the hyperparameters on the training set. To efficiently explore the hyperparameter space, I used Randomized Grid Search CV. This involves randomly sampling hyperparameter combinations from the hyperparameter grid, and then using a 5-fold cross-validation approach to estimate the model’s MAE. Though Randomized Grid Search CV does not exhaustively explore the entire hyperparameter space, it is computationally inexpensive, and often achieves a reasonably good level of performance. After conducting this process for each model type and feature set, I got one final estimate of the model’s generalizability by computing the MAE and MAPE on the held out test set.
4.3 Generative Model
For the generative model, I chose GPT-2. My rationale behind GPT-2 was to better understand how to interact with the model, and also gain an appreciation of transformer-based models. Finally, I also wanted to see whether a famous model such as GPT-2 would be able to generate convincing TED talks. My GPT-2 implementation was taken from Huggingface’s transformers repository.
5. Results
5.1 Audience Engagement Prediction
For my final Audience Engagement Predictive model, I chose a Support Vector Machine Regression model with C = 1.4 and L1 Regularized Loss, in combination with a 200-dimensional pre-trained GLoVE embedding as features. I preprocessed features by standard scaling them according to the following equation: X_standard = (X – mu_x)/ sigma_X, where mu_x and sigma_x are the variable’s mean and standard deviation respectively. This had a MAE of 74.929, and a MAPE of 61.477. One of the advantages of this model, is a fast training time due to the Liblinear implementation, and and a fast prediction time as well. Best results from the other models may be viewed in the below table.
| Model | Features | MAE | MAPE |
| Logistic Regression | cvec-unigrams | 86.94 | 150.5 |
| Support Vector Machine | glove-wiki-200 | 74.93 | 61.48 |
| k-Nearest Neighbors | doc2vec-300 | 76.22 | 69.21 |
| Random Forest | doc2vec-50 | 75.41 | 60.87 |
| xgBoost | tfidf-4-grams | 79.55 | 60.49 |
5.2 Generative Model
To evaluate GPT-2, I fed in a few sentences from the middle of a TED talk into GPT2, and then compared the generated text to the actual remainder of the talk. I deliberately fed in sentences from the middle of each talk because by then the speaker is delivering his main message. For, example here are a few characteristic sentences from Al Gore’s 2006 TED talk about Averting the Climate Crisis:
”Now, what can you do? Reduce emissions in your home. Insulation, better design. Buy green electricity where you can. I mentioned automobiles—buy a hybrid. Use light rail. Figure out some of the other options that are much better. It´s important.Be a green consumer. You have choices with everything you buy, between things that have a harsh effect, or a much less harsh effect on the global climate crisis. Consider this: Make a decision to live a carbon-neutral life. It means reduce your carbon dioxide emissions with the full range of choices that you make. Next, consider making your business carbon-neutral. Integrate climate solutions into all of your innovations, whether you are from the technology, or entertainment, or design and architecture community. Invest sustainably.”
Al Gore – Averting the Climate Crisis (2006)
Below are the two completions generated by GPT-2:
- Don’t lose sight of the fact that it will all change for the better. Put the whole package. Invent a new way to reduce emissions, or use it as leverage in any kind of business model. I think this is not in the best interests of all consumers or perhaps not even the greatest of businesses. Score: 182.34
- Focus on the consumer, not everything in your business. Be your own CEO, rather than your own shareholder. If your business is a failure in its sustainability, consider switching some parts of life of that failure into renewable solutions. Score: 170.55

For your reference, Al Gore’s actual continuation of his speech is as follows:
”Become a catalyst of change. Teach others, learn about it, talk about it. Make our democracy work the way it´s supposed to work. Support the idea of capping carbon dioxide emissions — global warming pollution — and trading it.”
Al Gore – Averting the Climate Crisis (2006)
It is clear from the above that GPT-2 has picked up on Al Gore’s action oriented style of speaking; he is commanding the audience to action in the input segment of his speech, and this imperative voice is continued by GPT-2 in its generation. This highlights another major advantage of GPT-2: it is able to pick up on stylistic choices of individual speakers. Meanwhile, the audience engagement model quantitatively predicts the amount of audience engagement for each GPT-2 generated continuation.
6. Discussion
Using the above two models in conjunction allows a speaker to rapidly explore the space of ideas, and get a sense of which ideas would be the most thought-provoking to the crowd. Using the Audience Engagement Predictive model with the GPT-2 addresses an important shortcoming of GPT-2 generated text: a means of evaluating the quality of the text. Currently, it is common to simply read through a few samples of the generated text, and then pick whichever is most coherent. However, now, a speaker may use the predictive model as an added heuristic, in addition to a simple read through to pick a particular GPT-2 text generation. It is important to note that the goal of this application is not to generate convincing TED-talks in a standalone fashion. The objective is to have ”human in the loop Augmented Intelligence”, where a human uses this system to assist in his/her speaking efforts, rather than have a standalone general artificial intelligence. This addresses the coherence shortcoming of GPT-2, while providing a quantitative means of evaluating generated text.
7. Conclusion
Human in the loop augmented intelligence; the human still writes the talk, but now knows which ideas will generate the most audience interest.
– the big idea
In this paper, I hope I have convincingly demonstrated how a predictive model can be combined with a state-of-the-art generative model such as GPT-2 to solve an important problem faced by speakers worldwide. As next steps, I would encourage researchers to explore other quantitative metrics to evaluate text produced by generative models such as GPT-2. Secondly, I would encourage NLP practitioners to train a GPT-2 model specifically on the TED corpus to see whether it generates convincing speeches. Finally, predictions may seem opaque; it would be helpful for a speaker if they can see what are the various factors in a given section of GPT-2 generated text, that are driving the predicted score. Thus, a natural next step would be to explore methods to better interpret the scoring, possibly using Shapley values or various topic modelling techniques.
8. Code
The code for this paper is available at the following github repository:
https://github.com/MSIA/msia414-fall2020-talk-like-ted
References
- Sanjeev Arora, Yingyu Liang, and Tengyu Ma. 2016. A simple but tough-to-beat baseline for sentence embeddings.
- Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805
- Quoc Le and Tomas Mikolov. 2014. Distributed representations of sentences and documents. In International conference on machine learning, pages 1188–1196.
- Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. 2013. Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems, pages 3111–3119.
- Jeffrey Pennington, Richard Socher, and Christopher D Manning. 2014. Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pages 1532–1543.
- Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9.
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in neural information processing systems, pages 5998–6008