In a nutshell
WHO: Asset management firms, hedge funds, individual & institutional traders & investors
WHY: The FOMC statement has significant effects on the financial markets and careful analysis of the statement can help market participants discern the Fed’s monetary future policy intention and economic outlook
HOW: Natural language processing, OpenAI text embeddings, web scraping, bivariate correlation analysis
IMPACT: Market participants now have a numeric measure of the Fed’s monetary policy decision and economic outlook along with correlations to various securities. They can use this intelligence to make investment decisions.
You can view the interactive Tableau dashboard here.
1. Introduction

With the recent launch of OpenAI’s chatGPT, there is a significant buzz surrounding generative AI and large language models (LLMs). Generative AI and its attendant large language models are poised to re-imagine various industries. In the world of finance, generative AI tools can be used to rapidly analyze financial documents, formulate investment strategies, and develop communication. Recently, Bloomberg launched BloombergGPT, Bloomberg’s 50 billion parameter LLM purpose built from scratch for finance. BloombergGPT was trained on over forty years of financial data collected by Bloomberg. This model will assist Bloomberg in improving existing financial NLP tasks, such as sentiment analysis, named entity recognition, news classification, and question answering, among others. (ref)
In this project, I combine the Federal Open Market Committee’s (FOMC) statements with OpenAI’s powerful embeddings to create an indicator for the Fed’s mood. This insight can be used to make investment decisions. I also collect data from Yahoo Finance and analyze the correlations between the indices I built and various security prices.
2. What you need to know?
To gain an appreciation of the work done, it is necessary to have a grasp of both economic and data science knowledge. On the economics front, this includes the Fed’s role in executing monetary policy, the relationship between security prices & monetary policy, and how FOMC statements are structured. For data science, it is important to grasp concepts from natural language processing, text embeddings, and text analytics.
2.1 Economic Background
Please feel free to skip this section if you already have a working understanding of the Fed’s operation and monetary policy.
The Federal Reserve System is the U.S.’s central bank. Like any central bank, it is responsible for formulating & executing the nation’s monetary policy, serving as a lender of last resort, and stabilizing the economy in times of crisis. It periodically releases a statement that expresses the Fed’s monetary policy decision and its economic outlook. This statement is eagerly anticipated by the general public, and the financial markets are quick to respond. Additionally, various news media outlets conduct significant discussion & analysis around the sentiment and precise language used in the statement in order to discern the future direction of monetary policy.
Monetary policy is the set of tools that a nation’s central bank has available to promote sustainable economic growth by controlling the overall supply of money that is available to the nation’s banks, its consumers, and its businesses (ref). In the U.S., the Federal Reserve is responsible for adjusting monetary policy. Its Congressionally mandated objectives are “to promote maximum employment, stable prices, and moderate long-term interest rates”.
The three “levers” of monetary policy include adjusting bank’s reserve requirements, adjusting the discount rate, and influencing the interbank lending rate through open market operations.
Banks are required to maintain a fraction of their total deposits as reserves in the event depositors want to withdraw their money. The Federal Reserve can increase or decrease reserve requirements to affect the total amount of loans that banks can generate with a fixed level of deposits. The discount rate is the rate at which the Federal Reserve lends to banks. And lastly, federal funds are the funds that banks are required to maintain with the Federal Reserve. To adhere to the Fed’s requirements, banks with surplus funds lend out their funds overnight to other banks. The interest rate that arises from this capital market is known as the Federal Funds Rate. It is the fundamental interest rate in the economy and is closely tracked. Many consumer loans are indexed to the federal funds rate. The Federal Open Market Committee (FOMC) is responsible for setting the target federal funds rate. Then, the Federal Reserve uses open market operations to move the federal funds rate towards its target level. Open market operations involve the Fed becoming an active participant in the bond market by buying/selling bonds in an effort to change the federal funds rate to its target level.
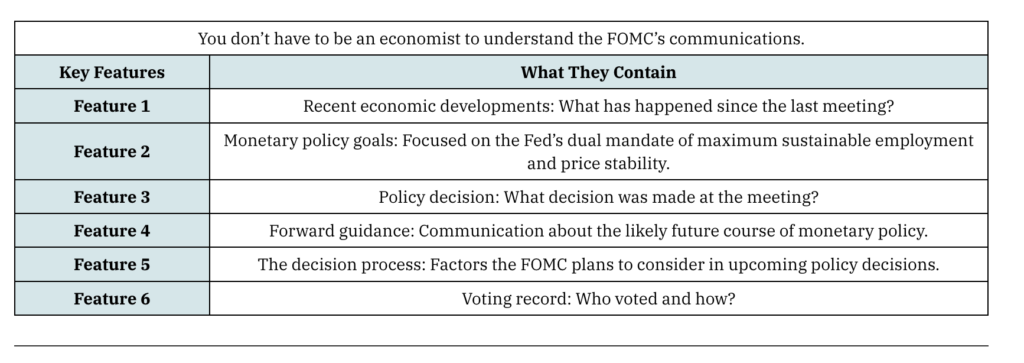
The FOMC meets every 6 weeks and releases a statement describing its target federal funds rate, its future monetary policy decision (termed “forward guidance”) and its economic outlook. Each FOMC statement has a fixed structure and delivers specific pieces of information. (ref) Naturally, the statement text is amenable to NLP & various text analytics techniques.
When the Fed follows contractionary monetary policy, it involves increasing interest rates and thus reducing the money supply to rein in inflation. When the Fed follows expansionary monetary policy, it involves reducing interest rates and thus expanding the money supply to grow the economy.
2.2 Data Science Background
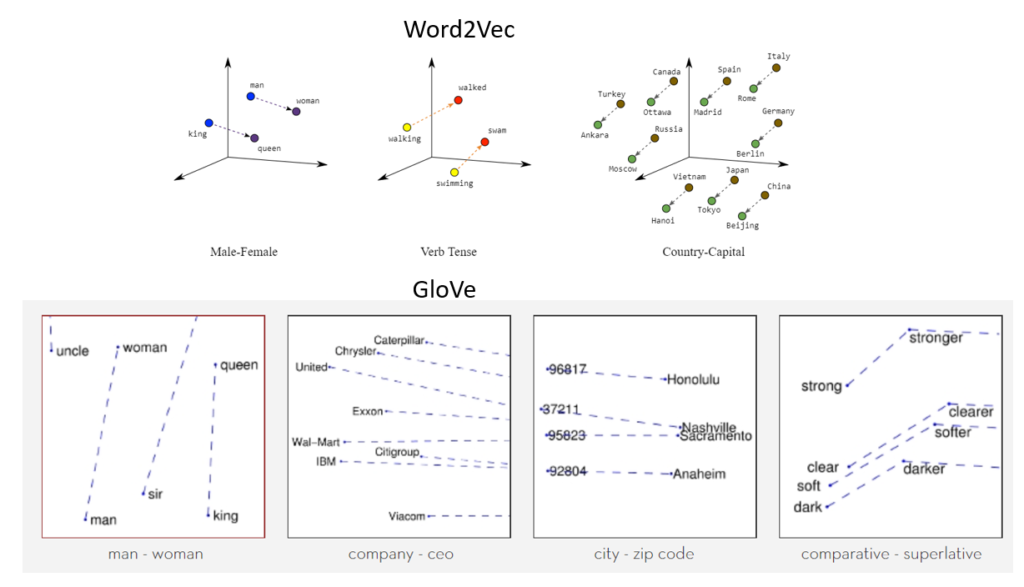
When OpenAI launched its landmark chatGPT model, there was a significant buzz surrounding generative AI and large language models. A core element of any large language model is the underlying text embedding model. A text embedding model provides a numerical representation of a text document. This numerical representation expands the universe of analytics & computations we can carry out on natural language. In simple words, a text embedding allows us to carry out mathematical operations on text as if they were mathematical objects. It does this by creating “embeddings”, which are mappings from words/documents to vectors. The mapping is done so as to preserve the semantics (meanings) of the documents. For example, vector embeddings allow us to express notions like like “queen” = “king” – “man” + “woman”. An early embedding model was the word2vec embedding model. OpenAI has provided access to its ada-2 embedding model through its API.
2.3 Related Work
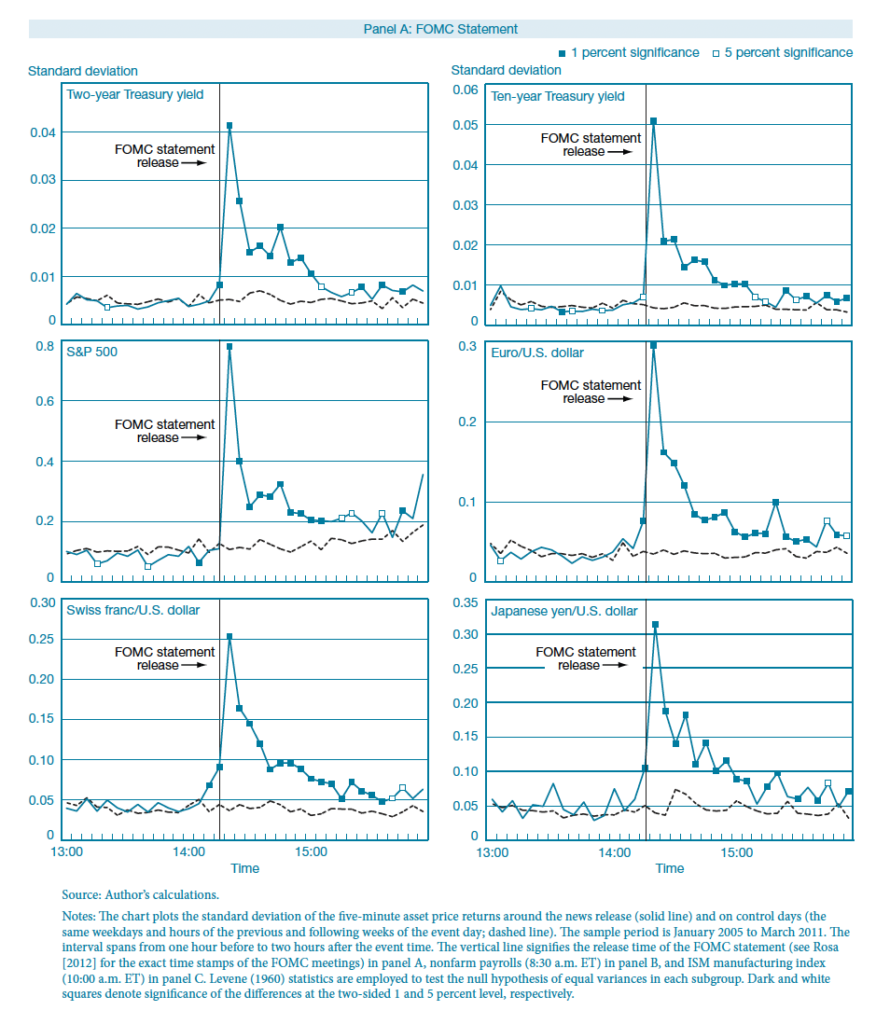
It is well-known that financial security prices are strongly affected by FOMC statements. In this paper, researchers observed steep spikes in the volatility of various securities in the minutes after the FOMC statement release.
Other projects analyze the FOMC statement using sentiment analysis techniques to glean the “mood of the Fed” (ref) or other AI-based methods (ref).
3. What data did I use?
My dataset consisted of FOMC statements scraped from the year 2000 to 2023 which amounted to around ~200 statements in total. I further obtained data corresponding to the following securities over the same time period (2000-2023) from Yahoo Finance:
- Fixed Income
- 13 week treasury bill
- 5 year treasury bond
- 10 year treasury bond
- Equities
- Dow Jones Industrial Average
- S&P 500
- Currencies/Foreign Exchange
- EUR/USD: Euros per US Dollar
- GBP/USD: British Pound Sterling per US Dollar
- JPY/USD: Japanese Yen per US Dollar
- CHF/USD: Swiss Franc per US Dollar
4. How did I build it?
4.1 Overall Solution Design
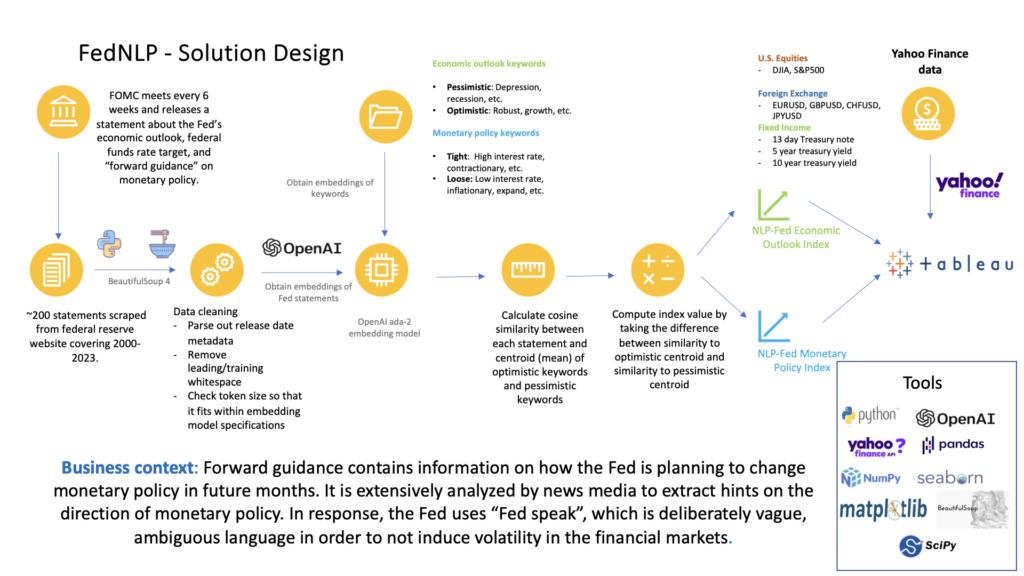
I built an end to end solution beginning with web-scraping the FOMC statements from the Fed’s website, cleaning & collating the data across all years, obtaining the text embeddings from OpenAI, and then finally computing an index. I also carried out ad-hoc normalizations to transform the index a suitable range. I then augmented the data with securities data from Yahoo Finance’s API. At last, I built a Tableau dashboard visualization to share insights with business stakeholders.
4.2 Web Scraping
I used the Python BeautifulSoup4 (BS4) library to scrape FOMC statements from the website. I sought out data from 2000 – 2024 in order to get an adequate sample size. The main challenge I encountered was differing formats between years. As a result, I grouped the statements into common templates and wrote custom code to extract the statements. Here are a few sample webpages from each year:

4.3 Data Cleaning
I kept data cleaning relatively simple. I carried out the following cleaning steps:
- Parse out metadata such as release data into a separate column. I used a simple regex extraction for that.
- Remove leading/trailing whitespace
- Check statement token size to ensure that it fits within the OpenAI embedding model context limit. I used the wittily named OpenAI library called TikToken for that. I used the cl100k_base tokenizer as that is the tokenizer used by the OpenAI’s ada-2 embedding model.
A token is a piece of text. There are several approaches to tokenization, but a simple technique is to split based on whitespace. As a result, “the cat jumped over the wall” will become [“the”, “cat”, “jumped”, “over”, “the”, “wall”]. Another approach to tokenization is to split based on characters. The sentence “the cat jumped over the wall” will thus become [“t”, “h”, “e”, “\s”, “c”, …, “l”]. The OpenAI tokenizer is slightly more complicated and uses a technique called “word pience” tokenization, which is a tad bit more complicated. You can view it here: https://platform.openai.com/tokenizer.
4.4 OpenAI API Embedding
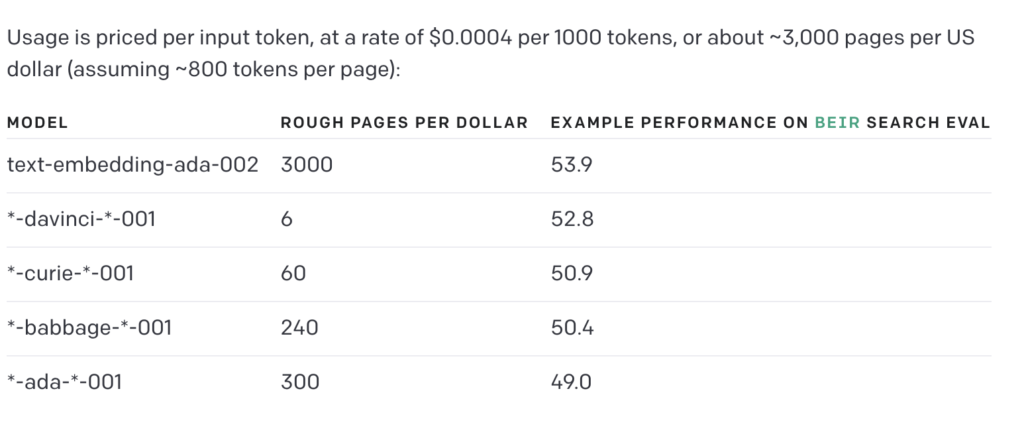
Now, we are ready to obtain vector embeddings for the FOMC statements. I decided to use OpenAI ada-2 embedding model. The ada-2 embedding model accepts a maximum token size of 8191 tokens and returns a vector of dimension 1536. On its website, OpenAI highly recommends its second generation of embedding models due to cost efficiencies and higher performance. The below table from OpenAI’s website compares the cost and performance of several of OpenAI’s embedding models. You can read more here (ref)
4.5 Index Computation
I not only got the vector embedding of each statement, but I also got the vector embedding of several key words. Each keyword was associated with an index and denoted a particular Fed sentiment.
I built two indices, one denoting the Fed’s economic outlook (FEDNLP-ECON) and the other denoting the Fed’s monetary policy mood (FEDNLP-MONPOL). I used the following keywords:
Economic outlook index (FEDNLP-ECON) keywords:
- Optimistic: [‘robust’, ‘strong’, ‘positive’, ‘optimistic’, ‘improving’, ‘resilient’]
- Pessimistic: [‘weak’, ‘fragile’, ‘uncertain’, ‘risky’, ‘sluggish’, ‘recession’]
Monetary policy (FEDNLP-MONPOL) keywords:
- Tight (contractionary/high interest rate) monetary policy: [‘inflation’, ‘tight monetary policy’, ‘contracting money supply’, ‘high interest rate policy’, ‘fiscal discipline’, ‘inflation target’]
- Loose (expansionary/low interest rate) monetary policy: [‘economic growth’, ‘job market’, ‘loose monetary policy’, ‘low interest rate policy’, ‘expanding money supply’, ‘economic stimulus measures’]
Once I got the vector embeddings of each keyword, I calculated the centroid (“average”) of all keywords sharing that sentiment. For example, I averaged all the keywords associated with an optimistic mood to obtain the “optimistic mood” centroid. I then did the same for the pessimistic mood keywords. I then repeated the process for tight and loose monetary policy key words. Thus, I had two different centroids for each index.
Finally, to calculate a raw index value for FEDNLP-ECON I used the following equation:
- FEDNLP-ECON raw index value = dist(statement, optimistic centroid) – dist(statement, pessimistic centroid)
- FEDNLP-MONPOL raw index value = dist(statement, tight monpol centroid) – dist(statement, loose monpol centroid)
dist(a, b) can be any distance metric. I chose to use the L2 norm (euclidean distance)

Lastly, I “shifted & scaled” each index using the following equation:
- shifted & scaled index value = (raw index value – midpoint)*scaling factor where the midpoint was the center of the range of the index [i.e. midpoint = (min index value + max index value)/2].
I chose to normalize the raw index values so that we get an index centered at zero and with neat, human readable numbers. I used a scaling factor of 10000.
4.6 Securities data from Yahoo Finance
In order to get a complete picture of how the financial markets move with my newly created index, I obtained securities data from Yahoo Finance. As discussed before, I chose the following securities because they are known to move significantly in response to changes in the Fed’s monetary policy. I got some inspiration from the following paper published by the New York Fed.
- Fixed Income
- 13 week treasury bill
- 5 year treasury bond
- 10 year treasury bond
- Equities
- Dow Jones Industrial Average
- S&P 500
- Currencies/Foreign Exchange
- EUR/USD: Euros per US Dollar
- GBP/USD: British Pound Sterling per US Dollar
- JPY/USD: Japanese Yen per US Dollar
- CHF/USD: Swiss Franc per US Dollar
Fortunately, Yahoo Finance has an unofficial API built by Ran Aroussi that makes it incredibly convenient to obtain securities data from Yahoo Finance. You can read more here: https://github.com/ranaroussi/yfinance
4.7 Visualization
Finally, to share my results with business stakeholders, I built an interactive Tableau visualization. You can play with it here. Here is a screenshot below:
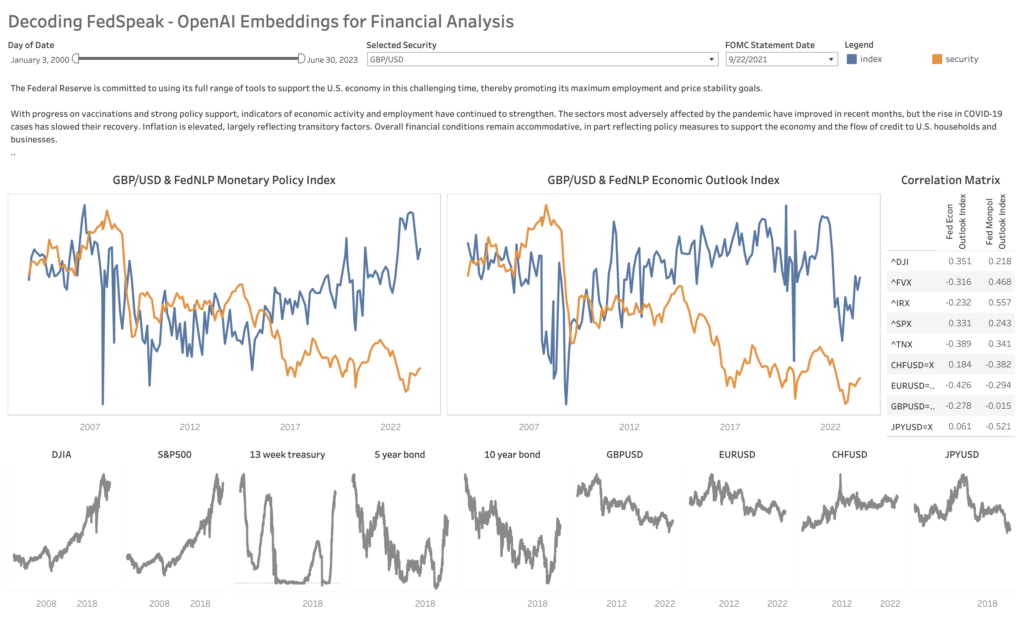
To make the graph look neat, I carried out some tweaks such as doing a min-max normalization to get values on the [-0.5,0.5] interval using the following equation:
- min_max_normalized index value = [(scaled_shifted_index_value – min(scaled_shifted_index_value))/max(scaled_shifted_index_value) – min(scaled_shifted_index_value)] – 0.5
5. What I did I find?
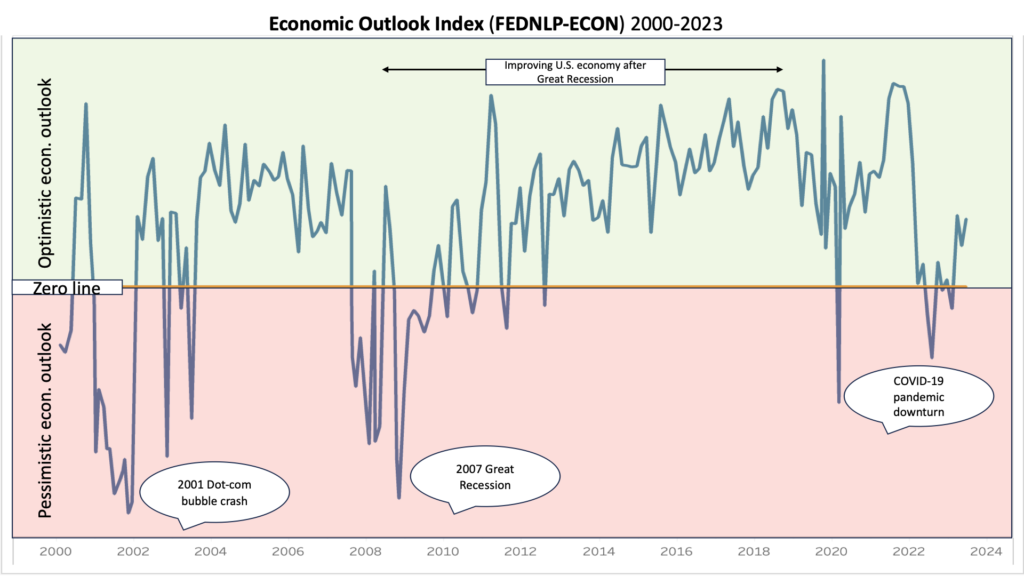
The economic outlook indicator (FEDNLP-ECON) was successful in identifying when an economic downturn occurred or boom period was in progress based solely on the Fed’s statements. For example, the below screenshot shows that FEDNLP-ECON was correctly able to detect the 2000 dot-com crash, the 2007 Great Recession, and the 2020 COVID-19 pandemic-induced recession. Similarly, it accurately reflected the sustained improving economic outlook in the economy after the 2007 Great Recession until the recent COVID-19 pandemic. It is important to note that FEDNLP-ECON does not reflect the current state of the economy, but rather the Fed’s economic outlook. As a result, FEDNLP-ECON steadily rises from 2007 onwards reflecting the steadily improving economic outlook.
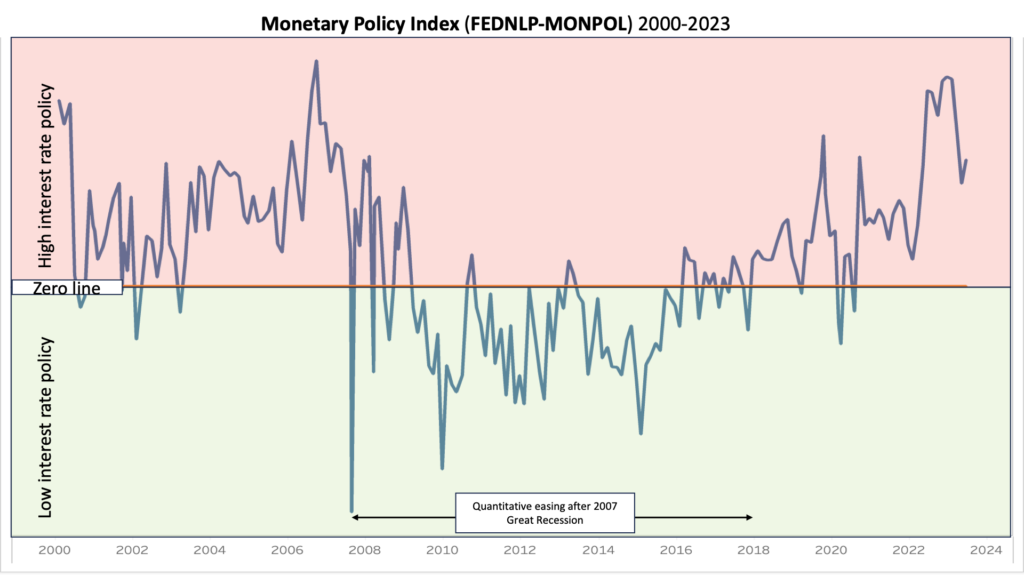
Similarly, the monetary policy indicator (FEDNLP-MONPOL) was correctly able to discern when the Fed was pursuing a contractionary vs. an expansionary policy. For example, it was accurately able to pick up on the Fed’s sustained pursuit of an expansionary policy (the “quantitative easing” era) as a response to the 2007 Great Recession. FEDNLP-MONPOL also identified the contractionary policy pursued by the Fed during the pre-2007 growth years. Moving forward, it also detected the expansionary policy the Fed pursued in response to the COVID-19 pandemic.
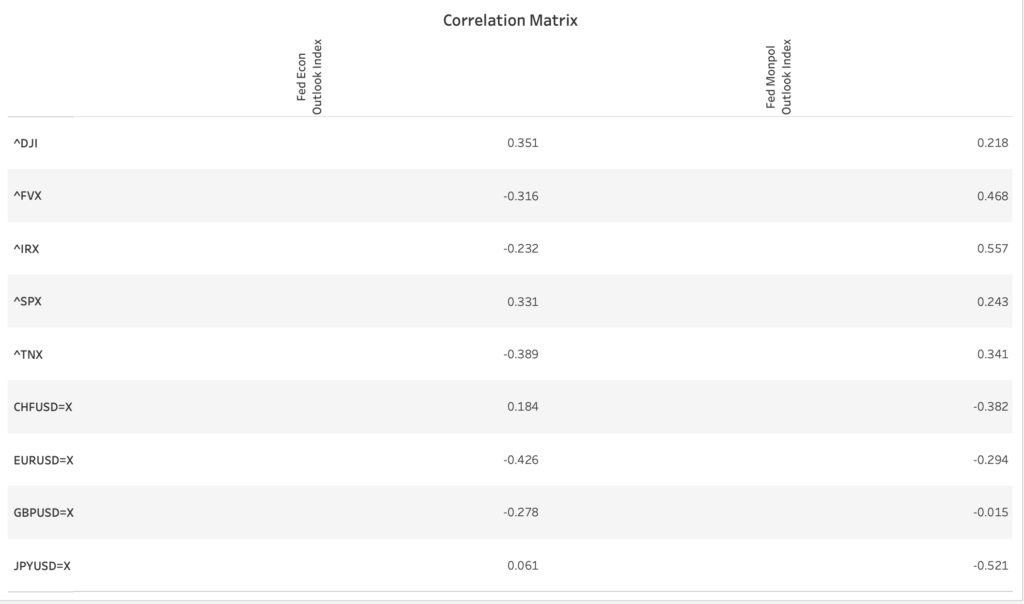
These findings are also reflected in the asset price correlations, especially with respect to FEDNLP-MONPOL. For example, the 13 week, 5 year, and 10 year treasury yield are strongly positively correlated with FEDNLP-MONPOL. So, for instance, when FEDNLP-MONPOL is above 0 (i.e. a contractionary policy), 13 week, 5 year, and 10 year treasure yields are also high. Why is this the case? A contractionary policy is associated with high interest rates; as a result, the fixed rate of return offered by a bond becomes less attractive thus reducing demand for bonds; bond prices fall which ultimately elevates the bond yield (ref). Similarly, FEDNLP-MONPOL and the currency exchange rates exhibit a strong negative correlation.
6. Why does it matter?
Both indicators allow us to extract a quantitative signal from a qualitative statement like the FOMC statement. This is insight can be used to influence investment decisions depending on the desired latency, and can also be used to rapidly detect trends over long time horizons.
As shown above, certain securities show a strong correlation with either FEDNLP-ECON or FEDNLP-MONPOL, and this insight can be used to trade those securities. Further work can evaluate correlations between lead/lagged versions of the indices to compute a leading indicator of security movements.
7. What should you remember?
Through creative use of the generative AI’s building blocks, it is possible to solve specific problem in finance. Here, we used OpenAI’s embedding model to convert a qualitative statement to a quantitative signal that can be used to make financial decisions. These indices can be used to build an alterantive-data based investment or trading strategy.
At a higher level of abstraction, we can also use the same playbook (produce a quantitative signal from qualitative text using embeddings) and apply it to other data sources like SEC 10-K filings, executive communications, and company prospectuses.
References
- https://www.bloomberg.com/company/press/bloomberggpt-50-billion-parameter-llm-tuned-finance/
- https://www.investopedia.com/terms/m/monetarypolicy.asp
- https://www.stlouisfed.org/open-vault/2019/may/how-read-fomc-statement
- https://www.newyorkfed.org/medialibrary/media/research/epr/2013/0913rosa.pdf
- https://blogs.cfainstitute.org/investor/2023/01/18/machine-learning-and-fomc-statements-whats-the-sentiment/
- https://www.morganstanley.com/articles/mnlpfeds-sentiment-index-federal-reserve
- https://platform.openai.com/docs/guides/embeddings/what-are-embeddings
- https://github.com/ranaroussi/yfinance
- https://www.investopedia.com/ask/answers/061715/how-bond-yield-affected-monetary-policy.asp